Super Sense Tagging (SST)
Super-sense tagging (SST) is a Natural Language Processing task that consists of annotating each significant entity in a text, like nouns, verbs, adjectives and adverbs, within a general semantic taxonomy defined by the WordNet lexicographer classes (called super-senses). SST can be considered as a task half-way between Named-Entity Recognition (NER) and Word Sense Disambiguation (WSD): it is an extension of NER, since it uses a larger set of semantic categories, and it is an easier and more practical task with respect to WSD, that deals with very specific senses.
Closed subtask
In the closed subtask, we want to measure the accuracy in SS tagging, when only the corpus provided for training is used.
Open subtask
In the open subtask participants will be free to use any external resource in addition to the corpus provided for training; for example, instances of WordNet as well as other lexical or semantic resources.
Task materials
A corpus for Super-sense tagging was created starting from the Italian Syntactic-Semantic Treebank (ISST) by a semi-automatic correction and conversion process, followed by manual revision [LREC 2010]. ISST-SST (~320,000 tokens ) is freely available for the task and for research purposes. It will be used for training and development. The test will be performed on a smaller corpus obtained from the Italian Wikipedia.
Trial: input and output samples
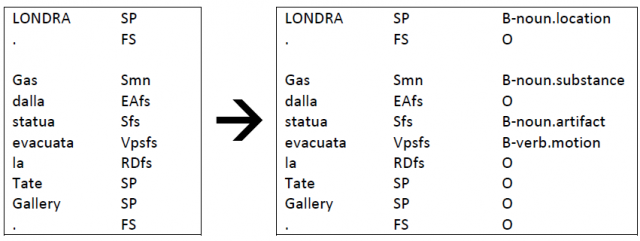
Task materials
Detailed Guidelines [18/08/2011]
Data Distribution
- Test data are available from the dedicated web page [04/10/2011]
- Training data can be downloaded from the dedicated web page
For any problem please contact: Maria Simi, simi[at]di.unipi.it
[LREC 2010] G. Attardi, S. Dei Rossi, G. Di Pietro, A. Lenci, S. Montemagni, M. Simi, A Resource and Tool for Super-sense Tagging of Italian Texts, Proceedings of 7th Language Resources and Evaluation Conference (LREC 2010), Malta, 17-23 May 2010.
Organizers
- Stefano Dei Rossi (Università di Pisa)
- Giulia Di Pietro (Università di Pisa)
- Maria Simi (Università di Pisa)