Lemmatisation
The deadline for the submission of results has been postponed to October 21.
Lemmatisation, the process of transforming each word-form into its corresponding lemma, is often considered a subproduct of a part-of-speech procedure that does not cause any particular problem.
The common view is that no particular ambiguities have to be resolved once the correct PoS-tag has been assigned. Unfortunately there are a lot of specific cases, at least in Italian, in which, given the same lexical class, we face a lemma ambiguity.
Some examples:
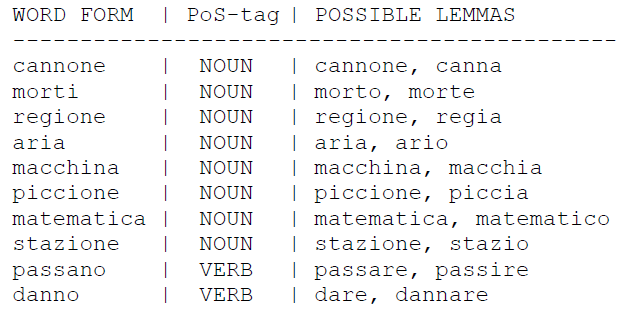
As you can see, homograph in verb forms belonging to different verbs, or noun valutative suffixation are some phenomena that create such kind of lemma ambiguities.
Even the use of morphological analysers based on large lexica, which are undoubtedly very useful for the PoS-tagging procedures, can create a lot of other ambiguities.
Certainly these phenomena are not pervasive and the total amount of such ambiguities is very limited, but we believe that it could be interesting to develop specific techniques to solve this generally ignored problem.
The data available for this task (the gold standard) are the same used for EVALITA 2007 PoS-tagging task and they consist of a small corpus of contemporary Italian containing about 150.000 tokens annotated manually with pos-tags and lemmas.
Each application will be evaluated using simple accuracy metrics.
Task materials
Detailed Guidelines [30/05/2011]
Data Distribution
For test and development data please contact the task organizer: fabio.tamburini[AT]unibo.it.
Organizer
Fabio Tamburini (Università di Bologna)